前言
写完上一篇文章想学 Node.js,stream 先有必要搞清楚 留下了悬念,stream对象数据流转的具体内容是什么?本篇文章将为大家进行深入讲解。
Buffer 探究
看一段之前使用stream操作文件的例子:
javascript
const fileName = path.resolve(__dirname, 'data.txt')
const stream = fs.createReadStream(fileName)
console.log('stream内容', stream)
stream.on('data', function(chunk) {
console.log(chunk instanceof Buffer)
console.log(chunk)
})
看一下打印结果,发现第一个 stream 是一个对象 ,部分内容。
javascript
_readableState: ReadableState {
objectMode: false,
highWaterMark: 16384,
buffer: BufferList { head: null, tail: null, length: 0 },
length: 0,
pipes: null,
pipesCount: 0,
flowing: true,
ended: false,
endEmitted: false,
reading: true,
sync: false,
needReadable: true,
emittedReadable: false,
readableListening: false,
resumeScheduled: false,
emitClose: false,
autoDestroy: false,
destroyed: false,
defaultEncoding: 'utf8',
awaitDrainWriters: null,
multiAwaitDrain: false,
readingMore: false,
decoder: null,
encoding: null,
...
}
第二个和第三个打印结果,
true
<Buffer e5 86 99 e5 85 a5 e6 88 90 e5 8a 9f ef bc 9a 6d 6a 31 32 33 34 35 36 e5 86 99 e5 85 a5 e5 86 99 e5 85 a5>
Buffer 对象,类似数组,它的元素为 16 进制的两位数,即 0 到 255 的数值。可以看出 stream 中流动的数据是 Buffer 类型,二进制数据,接下来开始我们的 Buffer 探索之旅。
什么是二进制
二进制是计算机最底层的数据格式,字符串,数字,视频,音频,程序,网络包等,在最底层都是用二进制来进行存储。这些高级格式和二进制之间,都可以通过固定的编码格式进行相互转换。
例如,C 语言中 int32 类型的十进制整数(无符号),就占用 32bit 即 4byte,十进制的 3 对应的二进制就是00000000 00000000 00000000 00000011。字符串也是同理,可以根据 ASCII 编码规则或者 unicode 编码规则(如 utf-8)等和二进制进行相互转换。总之,计算机底层存储的数据都是二进制格式,各种高级类型都有对应的编码规则和二进制进行相互转换。
node 中为什么会出现 Buffer 这个模块
在最初的javascript生态中,javascript还运行在浏览器端,对于处理 Unicode 编码的字符串数据很容易,但是对于处理二进制以及非Unicode编码的数据无能为力,但是对于Server端操作TCP/HTTP以及文件I/O的处理是必须的。我想就是因此在Node.js里面提供了Buffer类处理二进制的数据,可以处理各种类型的数据。
Buffer 模块的一个说明。
在 Node.js 里面一些重要模块 net、http、fs 中的数据传输以及处理都有 Buffer 的身影,因为一些基础的核心模块都要依赖 Buffer,所以在 node 启动的时候,就已经加载了 Buffer,我们可以在全局下面直接使用 Buffer,无需通过 require()。且 Buffer 的大小在创建时确定,无法调整。
Buffer 创建
在 NodeJS v6.0.0版本之前,Buffer实例是通过 Buffer 构造函数创建的,即使用 new 关键字创建,它根据提供的参数返回不同的 Buffer,但在之后的版本中这种声明方式就被废弃了,替代 new 的创建方式主要有以下几种。
1. Buffer.alloc 和 Buffer.allocUnsafe(创建固定大小的 buffer)
用 Buffer.alloc 和 Buffer.allocUnsafe 创建 Buffer 的传参方式相同,参数为创建 Buffer 的长度,数值类型。
javascript
// Buffer.alloc 和 Buffer.allocUnsafe 创建 Buffer
// Buffer.alloc 创建 Buffer,创建一个大小为6字节的空buffer,经过了初始化
const buf1 = Buffer.alloc(6)
// Buffer.allocUnsafe 创建 Buffer,创建一个大小为6字节的buffer,未经过初始化
const buf2 = Buffer.allocUnsafe(6)
console.log(buf1) // <Buffer 00 00 00 00 00 00>
console.log(buf2) // <Buffer 78 ab 13 4f 60 02>
通过代码可以看出,用 Buffer.alloc 和 Buffer.allocUnsafe 创建Buffer 是有区别的,Buffer.alloc 创建的 Buffer 是被初始化过的,即 Buffer 的每一项都用 00 填充,而 Buffer.allocUnsafe 创建的 Buffer 并没有经过初始化,在内存中只要有闲置的 Buffer 就直接 “抓过来” 使用。
Buffer.allocUnsafe 创建 Buffer 使得内存的分配非常快,但已分配的内存段可能包含潜在的敏感数据,有明显性能优势的同时又是不安全的,所以使用需格外 “小心”。
2、Buffer.from(根据内容直接创建 Buffer)
Buffer.from(str, ) 支持三种传参方式:
- 第一个参数为字符串,第二个参数为字符编码,如
ASCII、UTF-8、Base64等等。 - 传入一个数组,数组的每一项会以十六进制存储为
Buffer的每一项。 - 传入一个
Buffer,会将Buffer的每一项作为新返回Buffer的每一项。
说明:Buffer目前支持的编码格式
- ascii - 仅支持 7 位 ASCII 数据。
- utf8 - 多字节编码的 Unicode 字符
- utf16le - 2 或 4 个字节,小端编码的 Unicode 字符
- base64 - Base64 字符串编码
- binary - 二进制编码。
- hex - 将每个字节编码为两个十六进制字符。
传入字符串和字符编码:
javascript
// 传入字符串和字符编码
const buf = Buffer.from('hello', 'utf8')
console.log(buf) // <Buffer 68 65 6c 6c 6f>
传入数组:
javascript
// 数组成员为十进制数
const buf = Buffer.from([1, 2, 3])
console.log(buf) // <Buffer 01 02 03>
javascript
// 数组成员为十六进制数
const buf = Buffer.from([0xe4, 0xbd, 0xa0, 0xe5, 0xa5, 0xbd])
console.log(buf) // <Buffer e4 bd a0 e5 a5 bd>
console.log(buf.toString('utf8')) // 你好
在 NodeJS 中不支持 GB2312 编码,默认支持 UTF-8,在 GB2312 中,一个汉字占两个字节,而在 UTF-8 中,一个汉字占三个字节,所以上面 “你好” 的 Buffer 为 6 个十六进制数组成。
javascript
// 数组成员为字符串类型的数字
const buf = Buffer.from(['1', '2', '3'])
console.log(buf) // <Buffer 01 02 03>
传入的数组成员可以是任何进制的数值,当成员为字符串的时候,如果值是数字会被自动识别成数值类型,如果值不是数字或成员为是其他非数值类型的数据,该成员会被初始化为 00。
创建的 Buffer 可以通过 toString 方法直接指定编码进行转换,默认编码为 UTF-8。
传入 Buffer:
javascript
// 传入一个 Buffer
let buf1 = Buffer.from('hello', 'utf8')
let buf2 = Buffer.from(buf1)
console.log(buf1) // <Buffer 68 65 6c 6c 6f>
console.log(buf2) // <Buffer 68 65 6c 6c 6f>
console.log(buf1 === buf2) // false
console.log(buf1[0] === buf2[0]) // true
buf1[1] = 12
console.log(buf1) // <Buffer 68 0c 6c 6c 6f>
console.log(buf2) // <Buffer 68 65 6c 6c 6f>
当传入的参数为一个 Buffer 的时候,会创建一个新的 Buffer 并复制上面的每一个成员。
Buffer 为引用类型,一个 Buffer 复制了另一个 Buffer 的成员,当其中一个 Buffer 复制的成员有更改,另一个 Buffer 对应的成员不会跟着改变,说明传入buffer创建新的Buffer的时候是一个深拷贝的过程。
Buffer 的内存分配机制
buffer 对应于 V8 堆内存之外的一块原始内存
Buffer是一个典型的javascript与C++结合的模块,与性能有关的用 C++来实现,javascript 负责衔接和提供接口。Buffer所占的内存不是V8堆内存,是独立于V8堆内存之外的内存,通过C++层面实现内存申请(可以说真正的内存是C++层面提供的)、javascript 分配内存(可以说javascript层面只是使用它)。Buffer在分配内存最终是使用ArrayBuffer对象作为载体。简单点而言, 就是Buffer模块使用v8::ArrayBuffer分配一片内存,通过TypedArray中的v8::Uint8Array来去写数据。
内存分配的 8K 机制
- 分配小内存
说道 Buffer 的内存分配就不得不说Buffer的8KB的问题,对应buffer.js源码里面的处理如下:
javascript
Buffer.poolSize = 8 * 1024
function allocate(size) {
if(size <= 0 ) return new FastBuffer()
if(size < Buffer.poolSize >>> 1 )
if(size > poolSize - poolOffset) createPool()
var b = allocPool.slice(poolOffset,poolOffset + size)
poolOffset += size
alignPool()
return b
} else {
return createUnsafeBuffer(size)
}
}
源码直接看来就是以 8KB 作为界限,如果写入的数据大于 8KB 一半的话直接则直接去分配内存,如果小于 4KB 的话则从当前分配池里面判断是否够空间放下当前存储的数据,如果不够则重新去申请 8KB 的内存空间,把数据存储到新申请的空间里面,如果足够写入则直接写入数据到内存空间里面,下图为其内存分配策略。
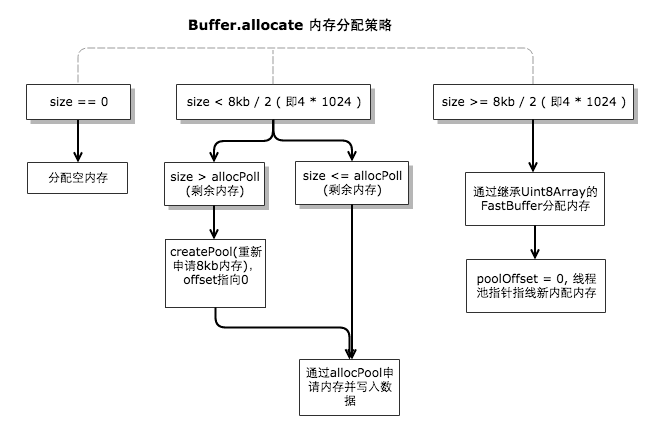
看内存分配策略图,如果当前存储了 2KB 的数据,后面要存储 5KB 大小数据的时候分配池判断所需内存空间大于 4KB,则会去重新申请内存空间来存储 5KB 数据并且分配池的当前偏移指针也是指向新申请的内存空间,这时候就之前剩余的 6KB(8KB-2KB)内存空间就会被搁置。至于为什么会用8KB作为存储单元分配,为什么大于8KB按照大内存分配策略,在下面Buffer内存分配机制优点有说明。
- 分配大内存
还是看上面那张内存分配图,如果需要超过8KB的Buffer对象,将会直接分配一个SlowBuffer对象作为基础单元,这个基础单元将会被这个大Buffer对象独占。
javascript
// Big buffer,just alloc one
this.parent = new SlowBuffer(this.length)
this.offset = 0
这里的SlowBuffer类实在C++中定义的,虽然引用 buffer 模块可以访问到它,但是不推荐直接操作它,而是用Buffer替代。这里内部parent属性指向的SlowBuffer对象来自Node自身C++中的定义,是C++层面的Buffer对象,所用内存不在V8的堆中
- 内存分配的限制
此外,Buffer单次的内存分配也有限制,而这个限制根据不同操作系统而不同,而这个限制可以看到node_buffer.h里面
C
static const unsigned int kMaxLength =
sizeof(int32_t) == sizeof(intptr_t) ? 0x3fffffff : 0x7fffffff;
对于 32 位的操作系统单次可最大分配的内存为 1G,对于 64 位或者更高的为 2G。
buffer 内存分配机制优点
Buffer真正的内存实在Node的C++层面提供的,javascript层面只是使用它。当进行小而频繁的Buffer操作时,采用的是8KB为一个单元的机制进行预先申请和事后分配,使得Javascript到操作系统之间不必有过多的内存申请方面的系统调用。对于大块的Buffer而言(大于8KB),则直接使用C++层面提供的内存,则无需细腻的分配操作。
Buffer 与 stream
stream 的流动为什么要使用二进制 Buffer
根据最初代码的打印结果,stream中流动的数据就是Buffer类型,也就是二进制。
原因一:
node官方使用二进制作为数据流动肯定是考虑过很多,比如在上一篇 想学 Node.js,stream 先有必要搞清楚文章已经说过,stream 主要的设计目的——是为了优化IO操作(文件IO和网络IO),对应后端无论是文件IO还是网络IO,其中包含的数据格式都是未知的,有可能是字符串,音频,视频,网络包等等,即使就是字符串,它的编码格式也是未知的,可能ASC编码,也可能utf-8编码,对于这些未知的情况,还不如直接使用最通用的格式二进制.
原因二:
Buffer对于http请求也会带来性能提升。
举一个例子:
javascript
const http = require('http')
const fs = require('fs')
const path = require('path')
const server = http.createServer(function(req, res) {
const fileName = path.resolve(__dirname, 'buffer-test.txt')
fs.readFile(fileName, function(err, data) {
res.end(data) // 测试1 :直接返回二进制数据
// res.end(data.toString()) // 测试2 :返回字符串数据
})
})
server.listen(8000)
将代码中的buffer-test文件大小增加到50KB左右,然后使用ab工具测试一下性能,你会发现无论是从吞吐量(Requests per second)还是连接时间上,返回二进制格式比返回字符串格式效率提高很多。为何字符串格式效率低?—— 因为网络请求的数据本来就是二进制格式传输,虽然代码中写的是 response 返回字符串,最终还得再转换为二进制进行传输,多了一步操作,效率当然低了。
Buffer 在 stream 数据流转充当的角色
我们可以把整个流(stream)和Buffer的配合过程看作公交站。在一些公交站,公交车在没有装满乘客前是不会发车的,或者在特定的时刻才会发车。当然,乘客也可能在不同的时间,人流量大小也会有所不同,有人多的时候,有人少的时候,乘客或公交车站都无法控制人流量。
不论何时,早到的乘客都必须等待,直到公交车接到指令可以发车。当乘客到站,发现公交车已经装满,或者已经开走,他就必须等待下一班车次。
总之,这里总会有一个等待的地方,这个等待的区域就是Node.js中的Buffer,Node.js不能控制数据什么时候传输过来,传输速度,就好像公交车站无法控制人流量一样。他只能决定什么时候发送数据(公交车发车)。如果时间还不到,那么Node.js就会把数据放入Buffer等待区域中,一个在 RAM 中的地址,直到把他们发送出去进行处理。
注意点:
Buffer虽好也不要瞎用,Buffer与String两者都可以存储字符串类型的数据,但是,String与Buffer不同,在内存分配上面,String直接使用v8堆存储,不用经过c++堆外分配内存,并且Google也对String进行优化,在实际的拼接测速对比中,String比Buffer快。但是Buffer的出现是为了处理二进制以及其他非Unicode编码的数据,所以在处理非utf8数据的时候需要使用到Buffer来处理。