一、缓存
欢迎来到「前端性能优化之旅」的第一站 —— 缓存。
当浏览器想要获取远程的数据时,我们的性能之旅就开始了。然而,我们并不会立即动身(发送请求)。在计算机领域,很多性能问题都会通过增加缓存来解决,前端也不例外。和许多后端服务一样,前端缓存也是多级的。下面让我们一起来具体看一看。
1. 本地数据存储
通过结合本地存储,可以在业务代码侧实现缓存。
对于一些请求,我们可以直接在业务代码侧进行缓存处理。缓存方式包括 localStorage、sessionStorage、indexedDB。把这块加入缓存的讨论也许会有争议,但利用好它确实能在程序侧达到一些类似缓存的能力。
例如,我们的页面上有一个日更新的榜单,我们可以做一个当日缓存:
javascript
// 当用户加载站点中的榜单组件时,可以通过该方法获取榜单数据
async function readListData() {
const info = JSON.parse(localStorage.getItem('listInfo'))
if (isExpired(info.time, +new Date())) {
const list = await fetchList()
localStorage.setItem(
'listInfo',
JSON.stringify({
time: +new Date(),
list: list,
})
)
return list
}
return info.list
}
localStorage 大家都比较了解了,indexedDB 可能会了解的更少一些。想快速了解 indexedDB 使用方式可以看这篇文章[1]。
从前端视角看,这是一种本地存储;但如果从整个系统的维度来看,很多时候其实也是缓存链条中的一环。对于一些特殊的、轻量级的业务数据,可以考虑使用本地存储作为缓存。
2. 内存缓存(Memory)
当你访问一个页面及其子资源时,有时候会出现一个资源被使用多次,例如图标。由于该资源已经存储在内存中,再去请求反而多此一举,浏览器内存则是最近、最快的响应场所。
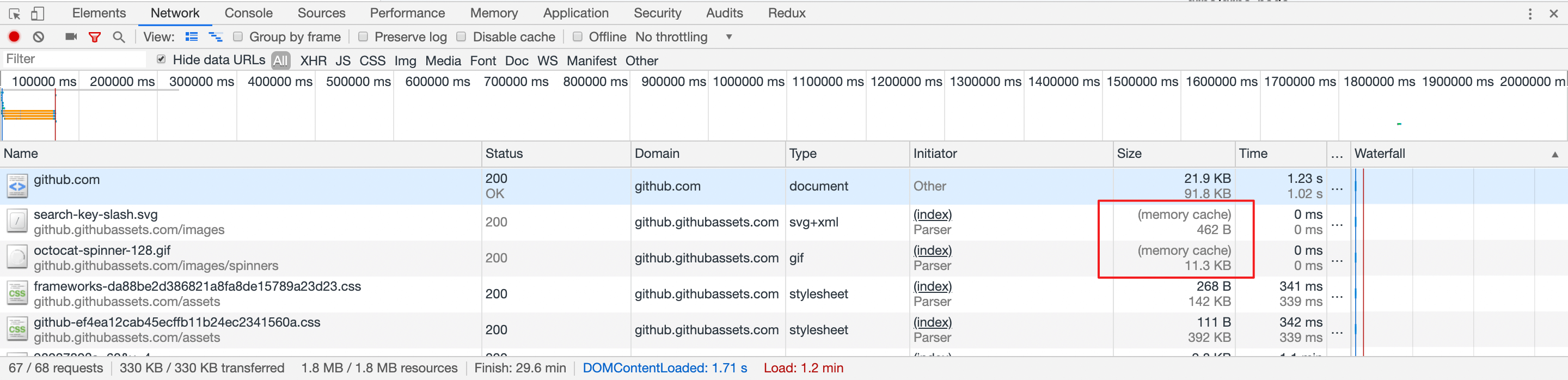
内存缓存并无明确的标准规定,它与 HTTP 语义下的缓存关联性不大,算是浏览器帮我们实现的优化,很多时候其实我们意识不到。
对内存缓存感兴趣,可以在这篇文章[2]的 Memory Cache 部分进一步了解。
3. Cache API
当我们没有命中内存缓存时,是否就开始发送请求了呢?其实不一定。
在这时我们还可能会碰到 Cache API 里的缓存,提到它就不得不提一下 Service Worker 了。它们通常都是配合使用的。
首先明确一下,这层的缓存没有规定说该缓存什么、什么情况下需要缓存,它只是提供给了客户端构建请求缓存机制的能力。如果你对 PWA 或者 Service Worker 很了解,应该非常清楚是怎么一回事。如果不了解也没有关系,我们可以简单看一下:
首先,Service Worker 是一个后台运行的独立线程,可以在代码中启用
javascript
// index.js
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('./sw.js').then(function() {
// 注册成功
})
}
之后需要处理一些 Service Worker 的生命周期事件,而其中与这里提到的缓存功能直接相关的则是请求拦截:
javascript
// sw.js
self.addEventListener('fetch', function(e) {
// 如果有cache则直接返回,否则通过fetch请求
e.respondWith(
caches
.match(e.request)
.then(function(cache) {
return cache || fetch(e.request)
})
.catch(function(err) {
console.log(err)
return fetch(e.request)
})
)
})
以上代码会拦截所有的网络请求,查看是否有缓存的请求内容,如果有则返回缓存,否则会继续发送请求。与内存缓存不同,Cache API 提供的缓存可以认为是“永久性”的,关闭浏览器或离开页面之后,下次再访问仍然可以使用。
Service Worker 与 Cache API 其实是一个功能非常强大的组合,能够实现堆业务的透明,在兼容性上也可以做成渐进支持。还是非常推荐在业务中尝试的。当然上面代码简略了很多,想要进一步了解 Service Worker 和 Cache API 的使用可以看这篇文章[3]。同时推荐使用 Google 的 Workbox。
4. HTTP 缓存
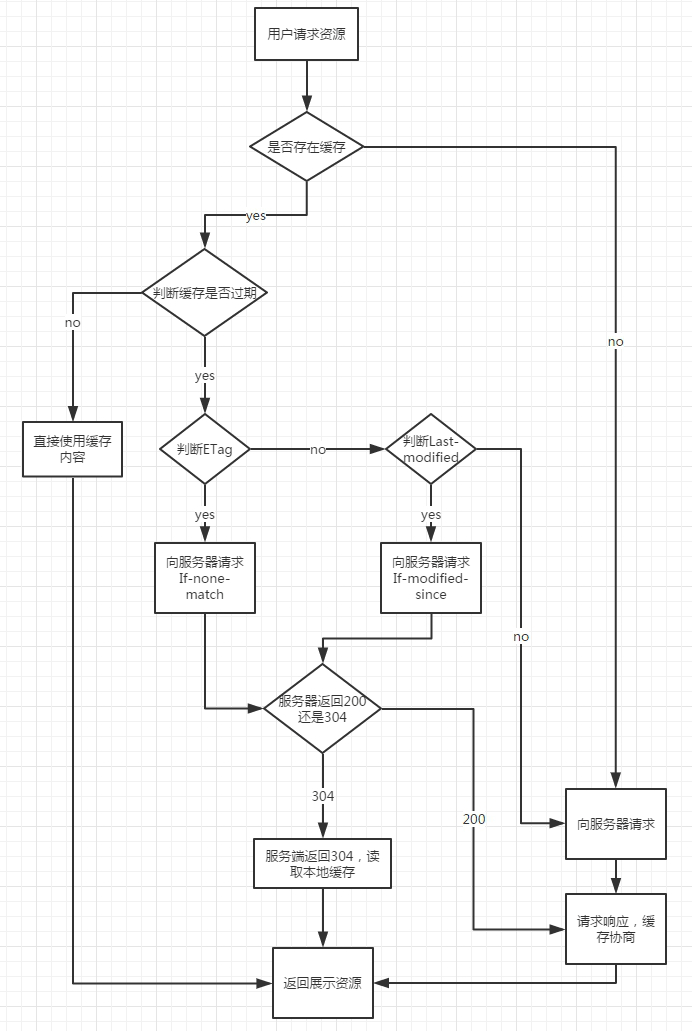
如果 Service Worker 中也没有缓存的请求信息,那么就会真正到 HTTP request 的阶段了。这个时候出现的就是我们所熟知的 HTTP 缓存规范。
HTTP 有一系列的规范来规定哪些情况下需要缓存请求信息、缓存多久,而哪些情况下不能进行信息的缓存。我们可以通过相关的 HTTP 请求头来实现缓存。
HTTP 缓存大致可以分为强缓存与协商缓存。
4.1. 强缓存
在强缓存的情况下,浏览器不会向服务器发送请求,而是直接从本地缓存中读取内容,这个“本地”一般就是来源于硬盘。这也就是我们在 Chrome DevTools 上经常看到的「disk cache」。
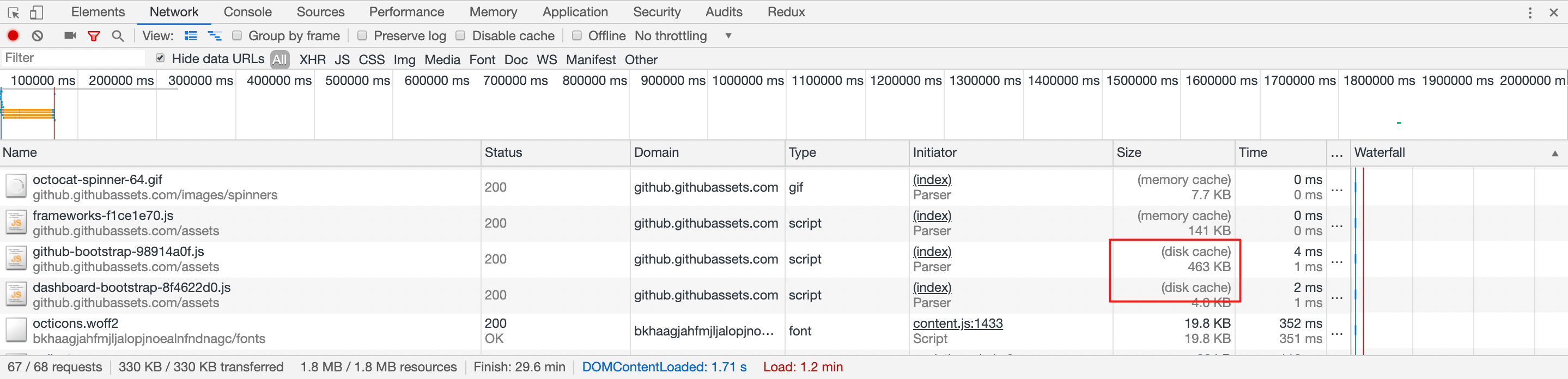
与其相关的响应头则是 Expires 和 Cache-Control。在 Expires 上可以设置一个过期时间,浏览器通过将其与当前本地时间对比,判断资源是否过期,未过期则直接从本地取即可。而 Cache-Control 则可以通过给它设置一个 max-age,来控制过期时间。例如,max-age=300 就是表示在响应成功后 300 秒内,资源请求会走强缓存。Cache-Control 出现于 HTTP / 1.1,优先级高于 Expires ,表示的是相对时间。
4.2. 协商缓存
你可能也感觉到了,强缓存不是那么灵活。如果我在 300 秒内更新了资源,需要怎么通知客户端呢?常用的方式就是通过协商缓存。
我们知道,远程请求慢的一大原因就是报文体积较大。协商缓存就是希望能通过先“问一问”服务器资源到底有没有过期,来避免无谓的资源下载。这伴随的往往会是 HTTP 请求中的 304 响应码。下面简单介绍一下实现协商缓存的两种方式:
一种协商缓存的方式是:服务器第一次响应时返回 Last-Modified,而浏览器在后续请求时带上其值作为 If-Modified-Since,相当于问服务端:XX 时间点之后,这个资源更新了么?服务器根据实际情况回答即可:更新了(状态码 200)或没更新(状态码 304)。
上面是通过时间来判断是否更新,如果更新时间间隔过短,例如 1s 一下,那么使用更新时间的方式精度就不够了。所以还有一种是通过标识 —— ETag。服务器第一次响应时返回 ETag,而浏览器在后续请求时带上其值作为 If-None-Match。一般会用文件的 MD5 作为 ETag。ETag 出现于 HTTP / 1.1, 优先级高于 Last-Modified 。
具体为什么要用ETag,主要出于下面几种情况考虑:
- 一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
- 某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
- 某些服务器不能精确的得到文件的最后修改时间。
作为前端工程师,一定要善于应用 HTTP 缓存。如果想要了解更多关于 HTTP 缓存的内容,可以阅读这篇文章[4]。
上面这些的各级缓存的匹配机制里,都是包含资源的 uri 的匹配,即 uri 更改后不会命中缓存。也正是如此,我们目前在前端实践中都会把文件 HASH 加入到文件名中,避免同名文件命中缓存的旧资源。
5. Push Cache
假如很不幸,以上这些缓存你都没有命中,那么你将会碰到最后一个缓存检查 —— Push Cache。
Push Cache 其实是 HTTP/2 的 Push 功能所带来的。简言之,过去一个 HTTP 的请求连接只能传输一个资源,而现在你在请求一个资源的同时,服务端可以为你“推送”一些其他资源 —— 你可能在在不久的将来就会用到一些资源。例如,你在请求 www.sample.com 时,服务端不仅发送了页面文档,还一起推送了 关键 CSS 样式表。这也就避免了浏览器收到响应、解析到相应位置时才会请求所带来的延后。
不过 HTTP/2 Push Cache 是一个比较底层的网络特性,与其他的缓存有很多不同,例如:
- 当匹配上时,并不会在额外检查资源是否过期;
- 存活时间很短,甚至短过内存缓存(例如有文章提到,Chrome 中为 5min 左右);
- 只会被使用一次;
- HTTP/2 连接断开将导致缓存直接失效;
- ……
如果对 HTTP/2 Push 感兴趣,可以看看这篇文章[5]。
好了,到目前为止,我们可能还没有发出一个真正的请求。这也意味着,在缓存检查阶段我们就会有很多机会将后续的性能问题扼杀在摇篮之中 —— 如果远程请求都不必发出,又何须优化加载性能呢?
所以,审视一下我们的应用、业务,看看哪些性能问题是可以在源头上解决的。
不过很多时候,能通过缓存解决的问题只有一部分。所以下面我们会继续这趟旅行,目前我们已经有了一个好的开始,不是么?
参考资料
- A quick but complete guide to IndexedDB and storing data in browsers
- A Tale of Four Caches
- PWA 学习与实践:让你的 WebApp 离线可用
- 浏览器缓存机制:强缓存、协商缓存
- HTTP/2 push is tougher than I thought
- Caching best practices & max-age gotchas
- The Offline Cookbook (Service Worker)
- HTTP/2 ORG
- Web Caching Explained by Buying Milk at the Supermarket
- 深入理解浏览器的缓存机制