面试官:说说 React diff 的原理是什么?Fiber 架构的理解?
一、是什么
跟Vue一致,React通过引入Virtual DOM的概念,极大地避免无效的Dom操作,使我们的页面的构建效率提到了极大的提升
而diff算法就是更高效地通过对比新旧Virtual DOM来找出真正的Dom变化之处
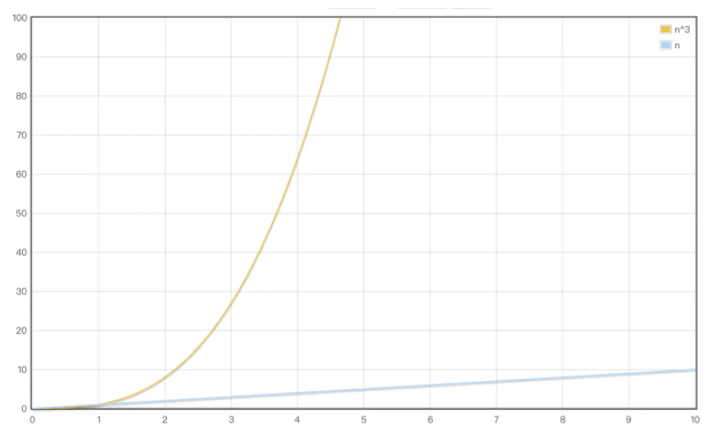
传统 diff 算法通过循环递归对节点进行依次对比,效率低下,算法复杂度达到 O(n^3),react将算法进行一个优化,复杂度降维O(n),两者效率差距如下图:
二、原理
react中diff算法主要遵循三个层级的策略:
tree 层级
component 层级
element 层级
tree 层级
DOM节点跨层级的操作不做优化,只会对相同层级的节点进行比较
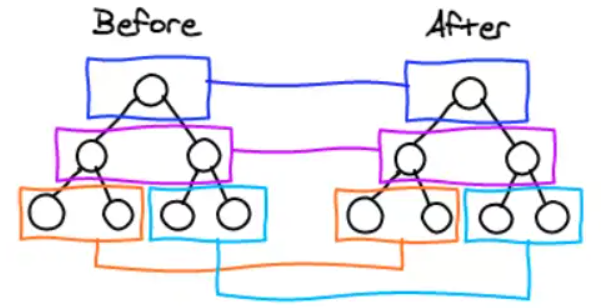
只有删除、创建操作,没有移动操作,如下图:
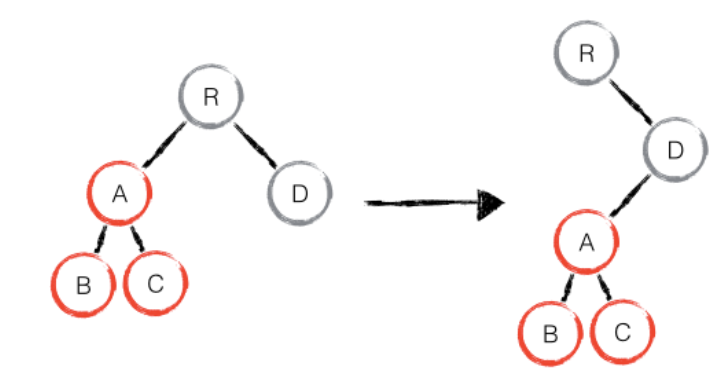
react发现新树中,R 节点下没有了 A,那么直接删除 A,在 D 节点下创建 A 以及下属节点
上述操作中,只有删除和创建操作
component 层级
如果是同一个类的组件,则会继续往下diff运算,如果不是一个类的组件,那么直接删除这个组件下的所有子节点,创建新的
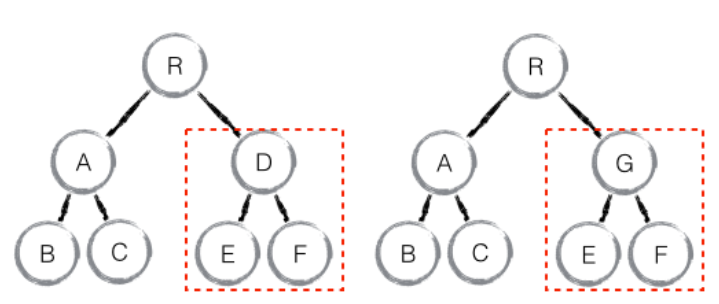
当component D换成了component G 后,即使两者的结构非常类似,也会将D删除再重新创建G
element 层级
对于比较同一层级的节点们,每个节点在对应的层级用唯一的key作为标识
提供了 3 种节点操作,分别为 INSERT_MARKUP(插入)、MOVE_EXISTING (移动)和 REMOVE_NODE (删除)
如下场景:
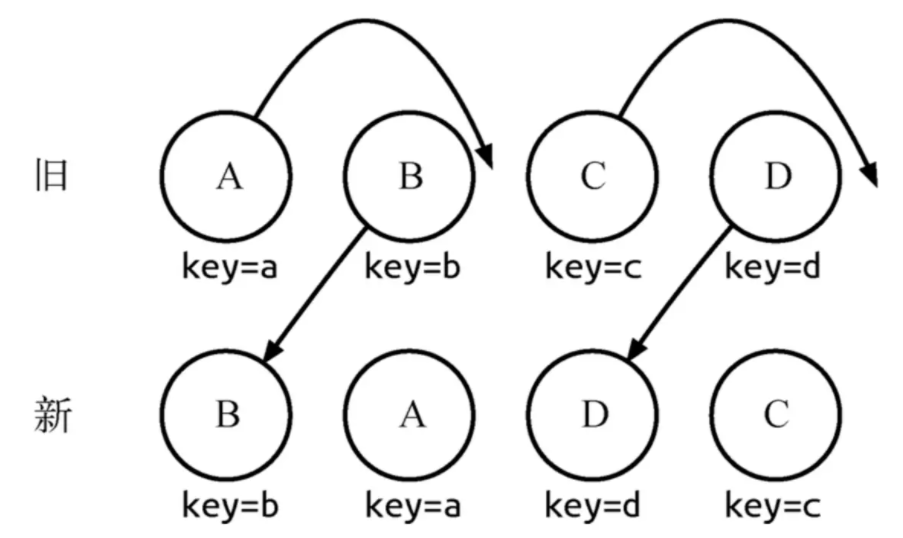
通过key可以准确地发现新旧集合中的节点都是相同的节点,因此无需进行节点删除和创建,只需要将旧集合中节点的位置进行移动,更新为新集合中节点的位置
流程如下表:
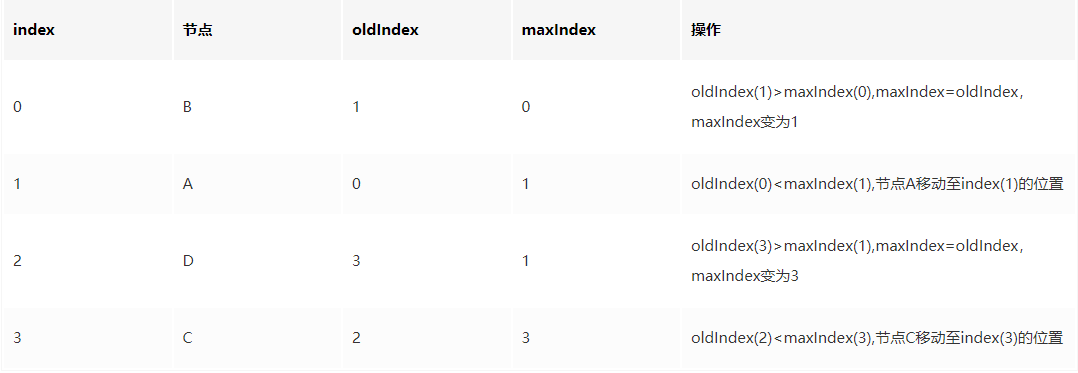
- index: 新集合的遍历下标。
- oldIndex:当前节点在老集合中的下标
- maxIndex:在新集合访问过的节点中,其在老集合的最大下标
如果当前节点在新集合中的位置比老集合中的位置靠前的话,是不会影响后续节点操作的,这时候节点不用动
操作过程中只比较 oldIndex 和 maxIndex,规则如下:
- 当 oldIndex>maxIndex 时,将 oldIndex 的值赋值给 maxIndex
- 当 oldIndex=maxIndex 时,不操作
- 当 oldIndex<maxIndex 时,将当前节点移动到 index 的位置
diff过程如下:
- 节点 B:此时 maxIndex=0,oldIndex=1;满足 maxIndex< oldIndex,因此 B 节点不动,此时 maxIndex= Math.max(oldIndex, maxIndex),就是 1
- 节点 A:此时 maxIndex=1,oldIndex=0;不满足 maxIndex< oldIndex,因此 A 节点进行移动操作,此时 maxIndex= Math.max(oldIndex, maxIndex),还是 1
- 节点 D:此时 maxIndex=1, oldIndex=3;满足 maxIndex< oldIndex,因此 D 节点不动,此时 maxIndex= Math.max(oldIndex, maxIndex),就是 3
- 节点 C:此时 maxIndex=3,oldIndex=2;不满足 maxIndex< oldIndex,因此 C 节点进行移动操作,当前已经比较完了
当 ABCD 节点比较完成后,diff过程还没完,还会整体遍历老集合中节点,看有没有没用到的节点,有的话,就删除
三、注意事项
对于简单列表渲染而言,不使用key比使用key的性能,例如:
将一个[1,2,3,4,5],渲染成如下的样子:
html
<div>1</div>
<div>2</div>
<div>3</div>
<div>4</div>
<div>5</div>
后续更改成[1,3,2,5,4],使用key与不使用key作用如下:
html
<!-- 1.加key -->
<div key="1">1</div>
<div key="1">1</div>
<div key="2">2</div>
<div key="3">3</div>
<div key="3">3</div>
========>
<div key="2">2</div>
<div key="4">4</div>
<div key="5">5</div>
<div key="5">5</div>
<div key="4">4</div>
<!-- 操作:节点2移动至下标为2的位置,节点4移动至下标为4的位置。 -->
<!-- 2.不加key -->
<div>1</div>
<div>1</div>
<div>2</div>
<div>3</div>
<div>3</div>
========>
<div>2</div>
<div>4</div>
<div>5</div>
<div>5</div>
<div>4</div>
<!-- 操作:修改第1个到第5个节点的innerText -->
如果我们对这个集合进行增删的操作改成[1,3,2,5,6]
html
<!-- 1.加key -->
<div key="1">1</div>
<div key="1">1</div>
<div key="2">2</div>
<div key="3">3</div>
<div key="3">3</div>
========>
<div key="2">2</div>
<div key="4">4</div>
<div key="5">5</div>
<div key="5">5</div>
<div key="6">6</div>
<!-- 操作:节点2移动至下标为2的位置,新增节点6至下标为4的位置,删除节点4。 -->
<!-- 2.不加key -->
<div>1</div>
<div>1</div>
<div>2</div>
<div>3</div>
<div>3</div>
========>
<div>2</div>
<div>4</div>
<div>5</div>
<div>5</div>
<div>6</div>
<!-- 操作:修改第1个到第5个节点的innerText -->
由于dom节点的移动操作开销是比较昂贵的,没有key的情况下要比有key的性能更好
四、Fiber 架构
React Fiber 是 Facebook 花费两年余时间对 React 做出的一个重大改变与优化,是对 React 核心算法的一次重新实现。从 Facebook 在 React Conf 2017 会议上确认,React Fiber 在 React 16 版本发布
在react中,主要做了以下的操作:
- 为每个增加了优先级,优先级高的任务可以中断低优先级的任务。然后再重新,注意是重新执行优先级低的任务
- 增加了异步任务,调用 requestIdleCallback api,浏览器空闲的时候执行
- dom diff 树变成了链表,一个 dom 对应两个 fiber(一个链表),对应两个队列,这都是为找到被中断的任务,重新执行
从架构角度来看,Fiber 是对 React核心算法(即调和过程)的重写
从编码角度来看,Fiber是 React内部所定义的一种数据结构,它是 Fiber树结构的节点单位,也就是 React 16 新架构下的虚拟DOM
一个 fiber就是一个 JavaScript对象,包含了元素的信息、该元素的更新操作队列、类型,其数据结构如下:
js
type Fiber = {
// 用于标记fiber的WorkTag类型,主要表示当前fiber代表的组件类型如FunctionComponent、ClassComponent等
tag: WorkTag,
// ReactElement里面的key
key: null | string,
// ReactElement.type,调用`createElement`的第一个参数
elementType: any,
// The resolved function/class/ associated with this fiber.
// 表示当前代表的节点类型
type: any,
// 表示当前FiberNode对应的element组件实例
stateNode: any,
// 指向他在Fiber节点树中的`parent`,用来在处理完这个节点之后向上返回
return: Fiber | null,
// 指向自己的第一个子节点
child: Fiber | null,
// 指向自己的兄弟结构,兄弟节点的return指向同一个父节点
sibling: Fiber | null,
index: number,
ref: null | (((handle: mixed) => void) & { _stringRef: ?string }) | RefObject,
// 当前处理过程中的组件props对象
pendingProps: any,
// 上一次渲染完成之后的props
memoizedProps: any,
// 该Fiber对应的组件产生的Update会存放在这个队列里面
updateQueue: UpdateQueue<any> | null,
// 上一次渲染的时候的state
memoizedState: any,
// 一个列表,存放这个Fiber依赖的context
firstContextDependency: ContextDependency<mixed> | null,
mode: TypeOfMode,
// Effect
// 用来记录Side Effect
effectTag: SideEffectTag,
// 单链表用来快速查找下一个side effect
nextEffect: Fiber | null,
// 子树中第一个side effect
firstEffect: Fiber | null,
// 子树中最后一个side effect
lastEffect: Fiber | null,
// 代表任务在未来的哪个时间点应该被完成,之后版本改名为 lanes
expirationTime: ExpirationTime,
// 快速确定子树中是否有不在等待的变化
childExpirationTime: ExpirationTime,
// fiber的版本池,即记录fiber更新过程,便于恢复
alternate: Fiber | null,
}
Fiber把渲染更新过程拆分成多个子任务,每次只做一小部分,做完看是否还有剩余时间,如果有继续下一个任务;如果没有,挂起当前任务,将时间控制权交给主线程,等主线程不忙的时候在继续执行
即可以中断与恢复,恢复后也可以复用之前的中间状态,并给不同的任务赋予不同的优先级,其中每个任务更新单元为 React Element 对应的 Fiber节点
实现的上述方式的是requestIdleCallback方法
window.requestIdleCallback()方法将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应
首先 React 中任务切割为多个步骤,分批完成。在完成一部分任务之后,将控制权交回给浏览器,让浏览器有时间再进行页面的渲染。等浏览器忙完之后有剩余时间,再继续之前 React 未完成的任务,是一种合作式调度。
该实现过程是基于 Fiber节点实现,作为静态的数据结构来说,每个 Fiber 节点对应一个 React element,保存了该组件的类型(函数组件/类组件/原生组件等等)、对应的 DOM 节点等信息。
作为动态的工作单元来说,每个 Fiber 节点保存了本次更新中该组件改变的状态、要执行的工作。
每个 Fiber 节点有个对应的 React element,多个 Fiber节点根据如下三个属性构建一颗树:
javascript
// 指向父级Fiber节点
this.return = null
// 指向子Fiber节点
this.child = null
// 指向右边第一个兄弟Fiber节点
this.sibling = null
通过这些属性就能找到下一个执行目标